Perceptions of Language Technology Failures from South Asian English Speakers
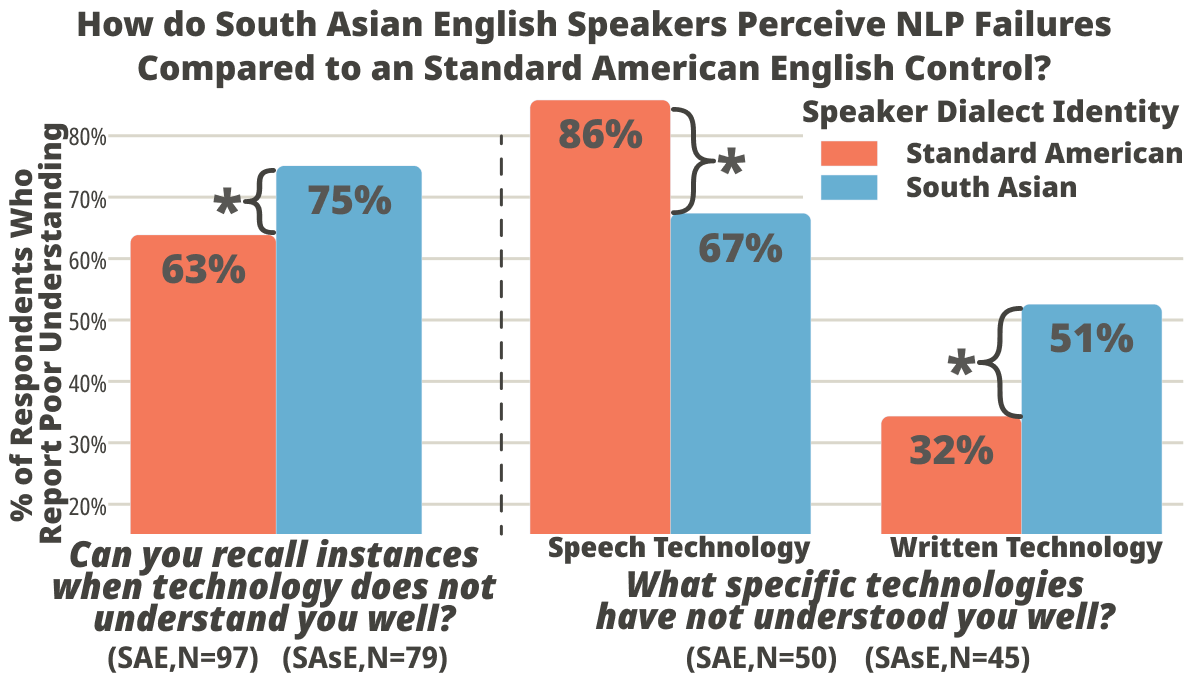
This user-centric NLP study shows qualitatively that language technologies are not dialect invariant. They often fail for speakers of non-standard English varieties, misunderstanding both individual words and the syntax of phrases. Compared with speakers of Standard American English (SAE), speakers of non-standard varieties report more failures with written technologies.
Multi-VALUE: A Framework for Cross-Dialectal English NLP
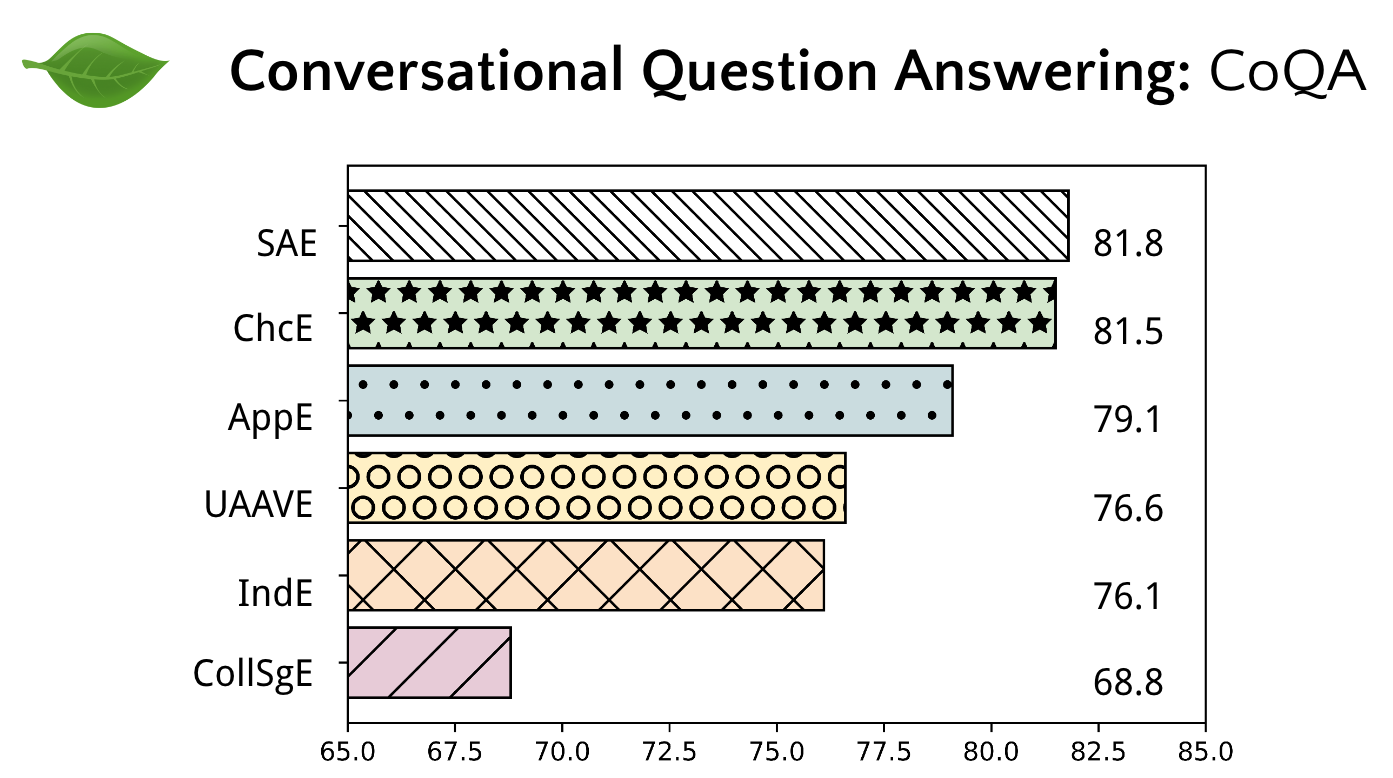
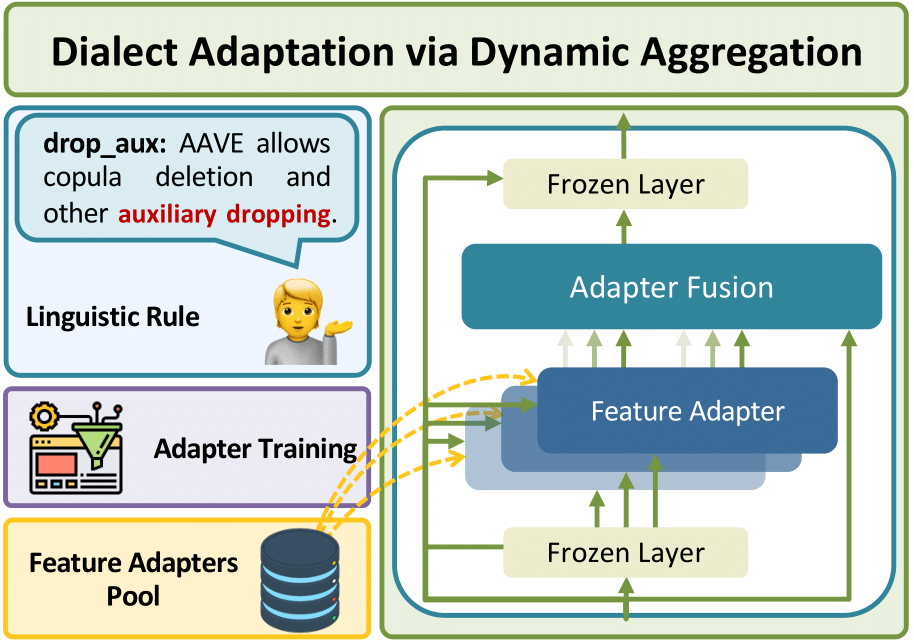
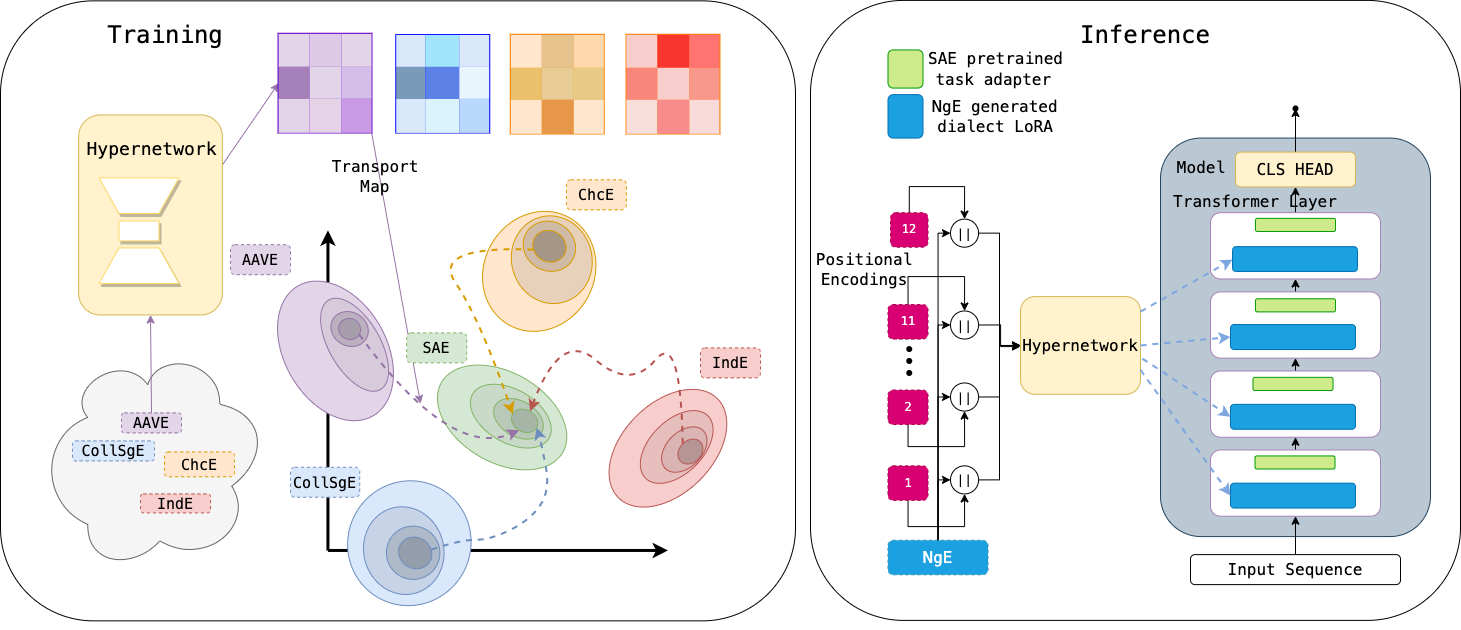
These value-nlp stress test experiments show quantitatively that many text-based NLP systems are not dialect invariant, with notable performance drops for widely-spoken varieties like Indian English and Colloquial Singapore English. This work also shows how to address disparities with data augmentation.
How can I set up value-nlp?
Use the following demo to start using Multi-VALUE.
Installation
pip install value-nlp
Demo
[VECTOR DIALECT] Southeast American enclave dialects (abbr: SEAmE)
Region: United States of America
Latitude: 34.2
Longitude: -80.9
'I done talked with them yesterday'
{(2, 7): {'value': 'done talked','type': 'completive_done'}}
Acknowledgements
This is a collaborative effort across Stanford University, Georgia Tech, Harvard University, and Amazon AI.

